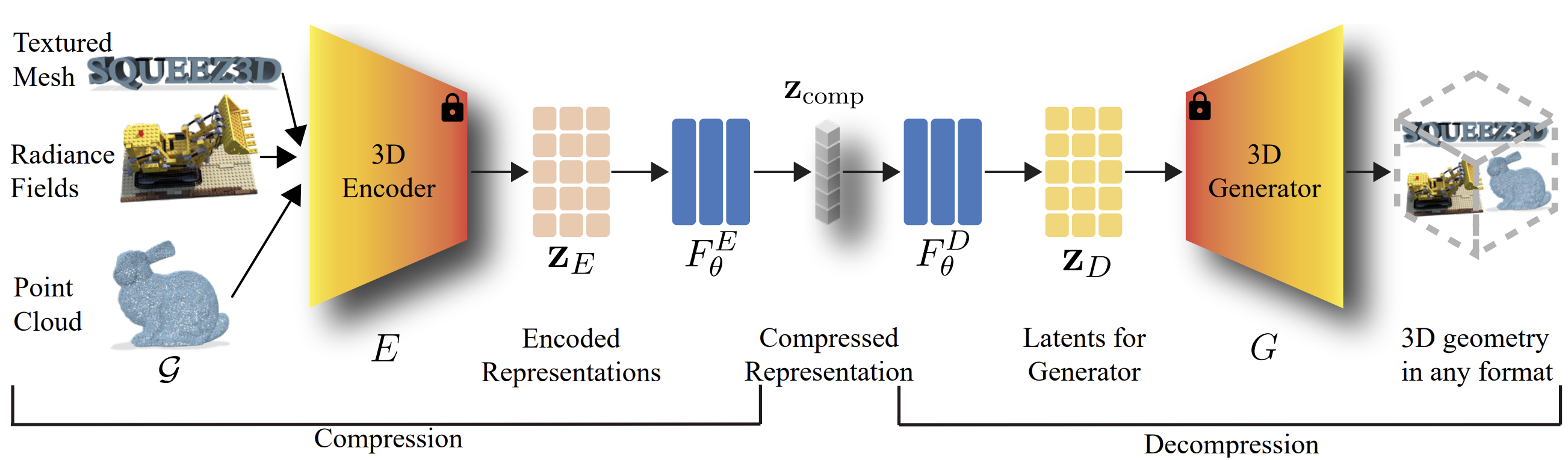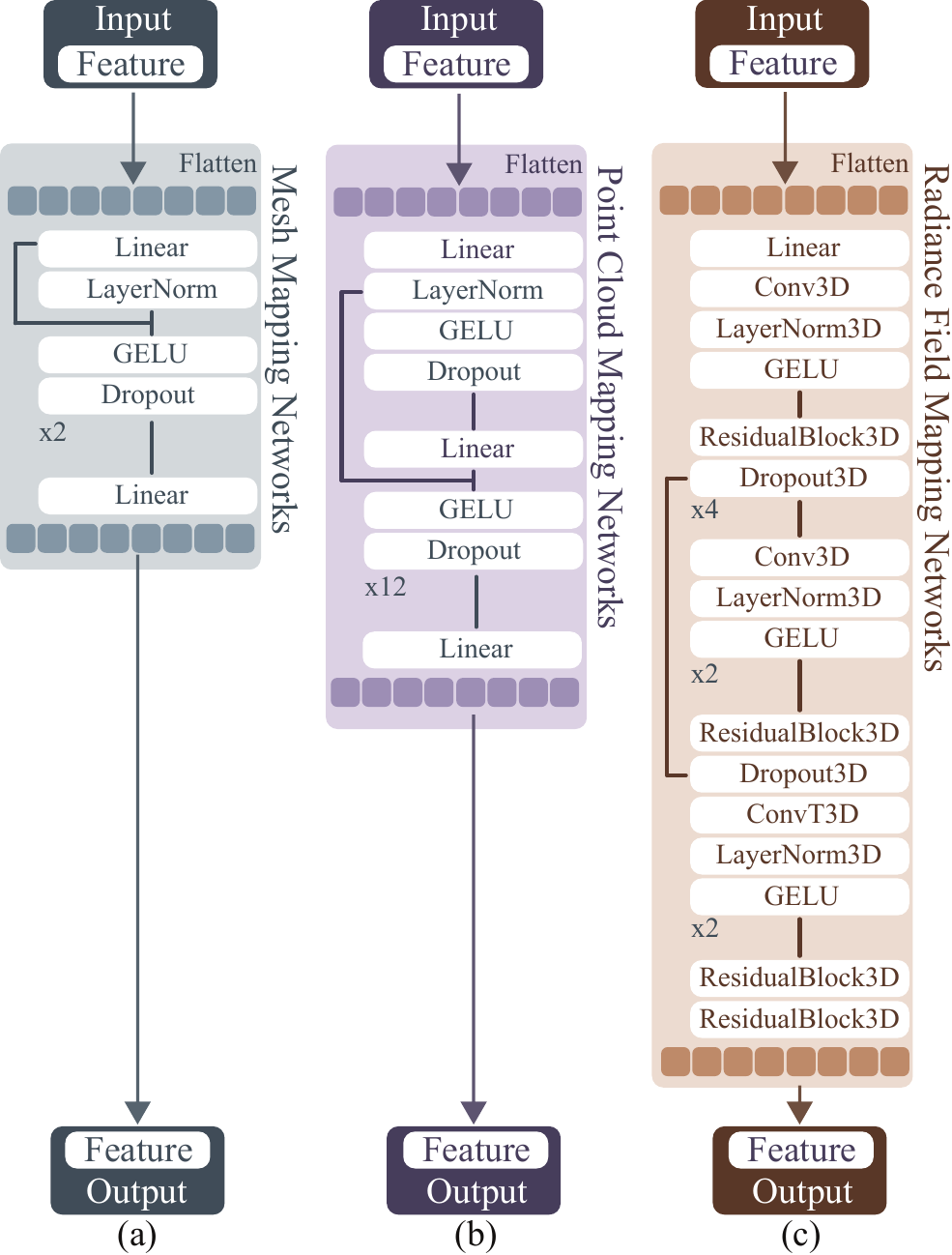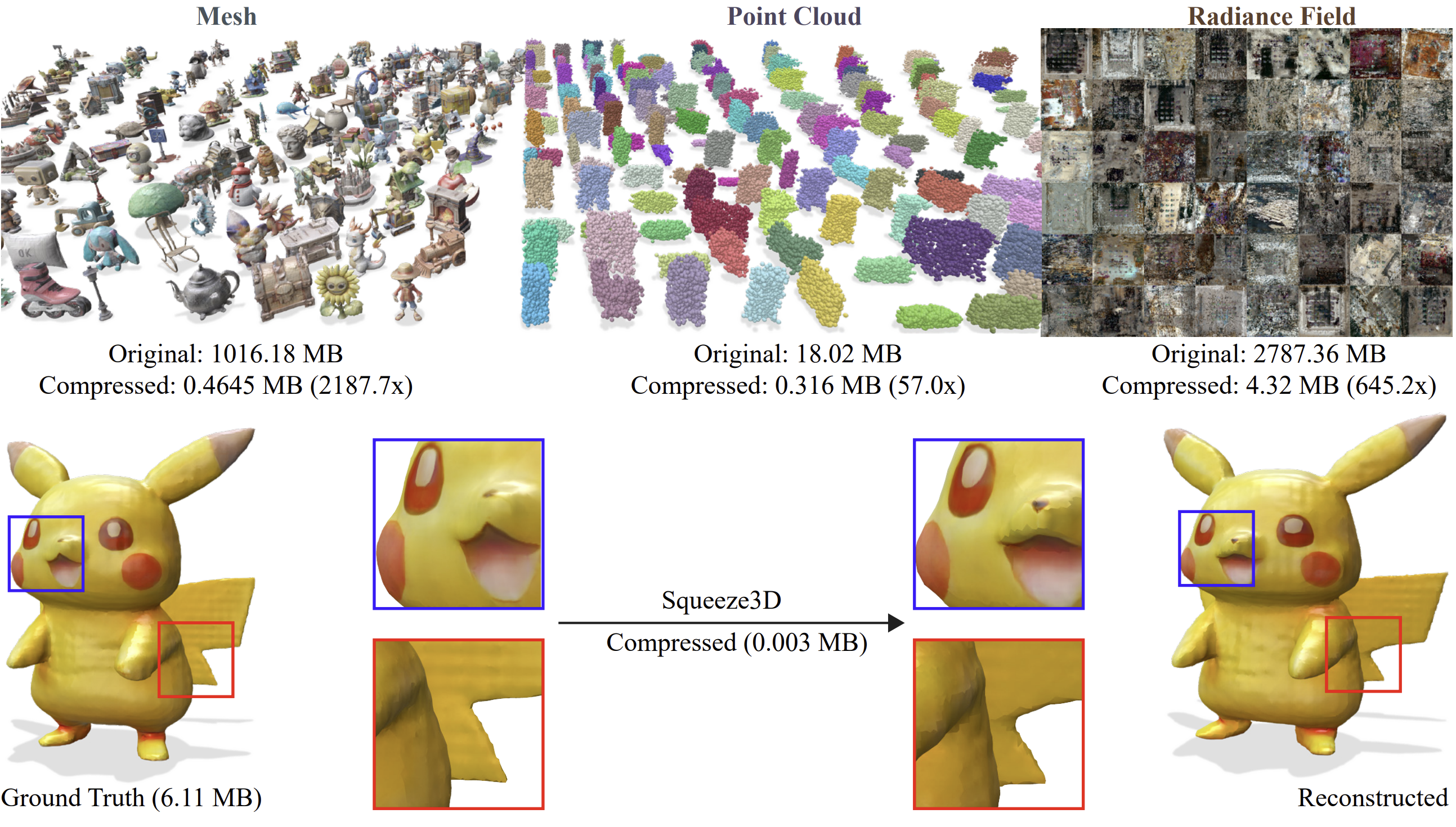
🎯 To the best of our knowledge, this is the first framework that leverages pre-existing pre-trained generative models to enable extreme compression of 3D data.
🔗 We demonstrate the feasibility of establishing correspondences between disparate latent manifolds originating from neural architectures with fundamentally different structures, optimization objectives, and training distributions.
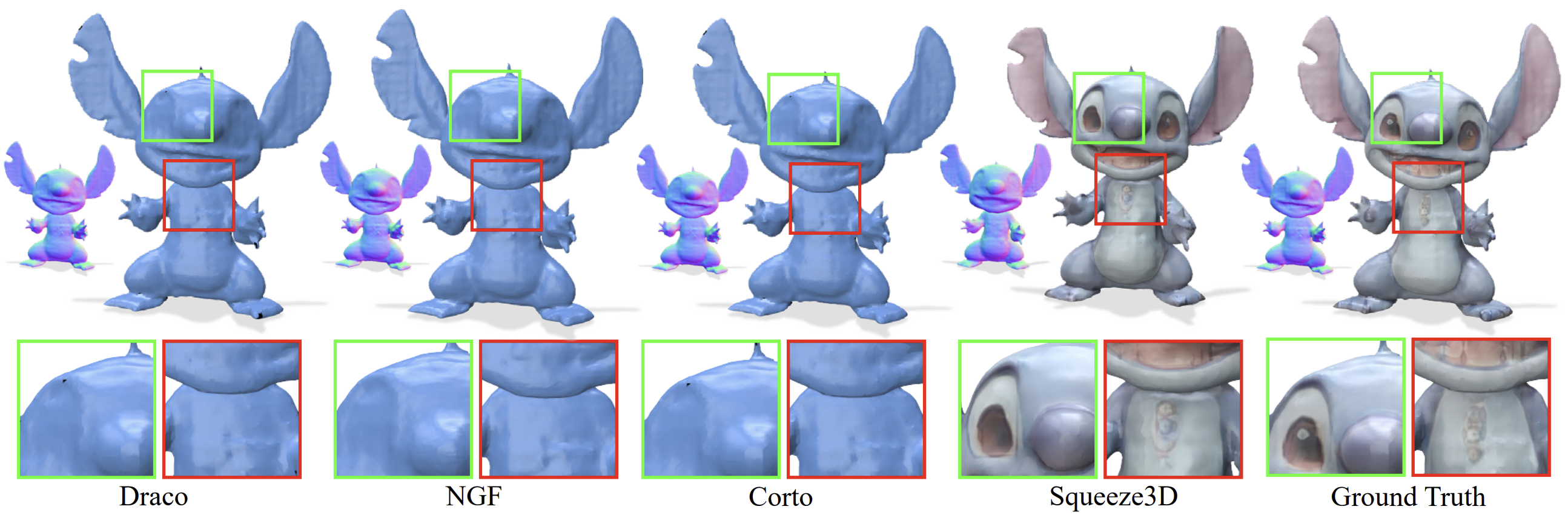
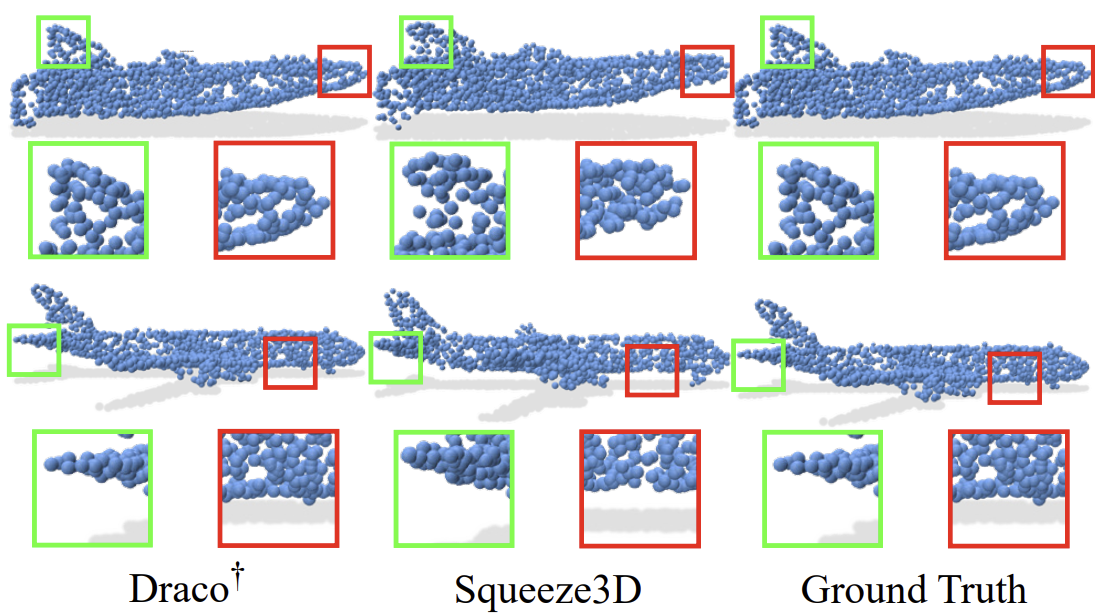
📊 We evaluate Squeeze3D for mesh, point cloud, and radiance field compression and demonstrate that generative models are a promising approach for extreme compression of 3D models. Squeeze3D can be flexibly extended to different encoders, generative models, and 3D formats.